If you have been involved in hands on database development for a while, or in any kind of BI / reporting initiative, you probably already know this. Nulls are evil (or at the very least mischievous).
A null value in a database column is different than a blank, a white space or any multitude of other invisible characters. It is truly void, nothingness, the abyss…
The implications of leaving null values can be very confusing for downstream reporting development. Null values will cause problems when trying to aggregate numeric values, they will make joins fall apart and complicate the querying of any table where null values are involved. As a case in point, I set out to demonstrate below how four major databases handle (or not handle..) null values. The answer is the same in each case.
The use case I created is simple:
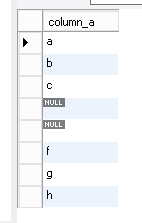
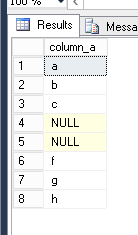
I created a table with 8 records in it. 2 of the records are null values. Then I queried the database with three simple questions:
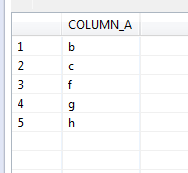
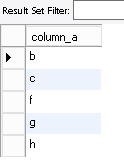
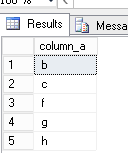
• How many values are there where the value is not ‘a’ – since one record has a value of a, I expected the answer to be 7
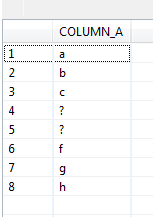
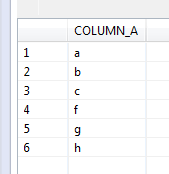
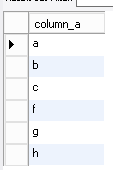
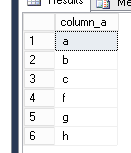
• Given a wild card search on the value, provide all records – I expected to get 8 records back from a “wild card” search on all records
• How many records are there in the table, counting the value field – I expected 8
All databases gave the same answer:
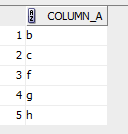
How many values are there where the value is not ‘a’ – 5. The 2 null values were not considered
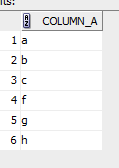
Given a wild card search on the value, provide all records – 6. The null records were ignored.
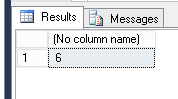
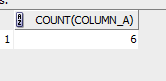
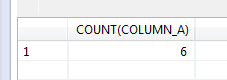
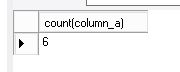
How many records are there in the table, counting the value field – 6. Yes, the database simply does not count the null values, as if they did not exist. Real nothingness…
Below are the test results in Oracle, SAP HANA, mySql and Sql Server. Beware of nulls…
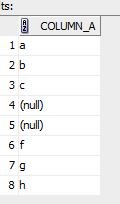
create table test_nulls (column_a varchar(255));
insert into test_nulls (column_a) values (‘a’);
insert into test_nulls (column_a) values (‘b’);
insert into test_nulls (column_a) values (‘c’);
insert into test_nulls (column_a) values (null);
insert into test_nulls (column_a) values (null);
insert into test_nulls (column_a) values (‘f’);
insert into test_nulls (column_a) values (‘g’);
insert into test_nulls (column_a) values (‘h’);
Oracle:
select * from test_nulls;
select * from test_nulls where column_a <> ‘a’;
select * from test_nulls where column_a like ‘%’;
select count(column_a) from test_nulls;
HANA:
create column table test_nulls (column_a varchar(255));
insert into test_nulls (column_a) values (‘a’);
insert into test_nulls (column_a) values (‘b’);
insert into test_nulls (column_a) values (‘c’);
insert into test_nulls (column_a) values (null);
insert into test_nulls (column_a) values (null);
insert into test_nulls (column_a) values (‘f’);
insert into test_nulls (column_a) values (‘g’);
insert into test_nulls (column_a) values (‘h’);
select * from test_nulls;
select * from test_nulls where column_a <> ‘a’;
select * from test_nulls where column_a like ‘%’;
select count(column_a) from test_nulls;
MySQL
select * from test_nulls;
select * from test_nulls where column_a <> ‘a’;
select * from test_nulls where column_a like ‘%’;
select count(column_a) from test_nulls;
Sql Server
select * from test_nulls;
select * from test_nulls where column_a <> ‘a’;
select * from test_nulls where column_a like ‘%’;
select count(column_a) from test_nulls;