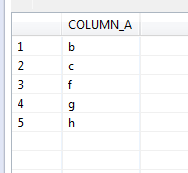
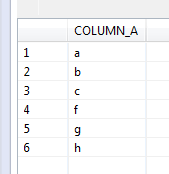
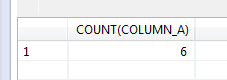
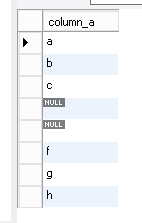
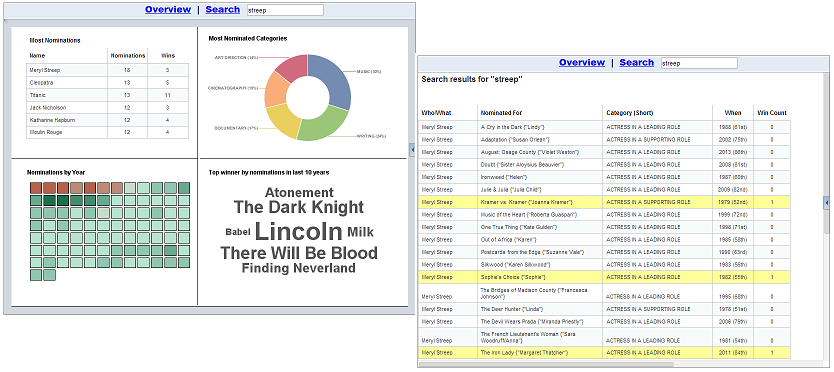
In this recalls dashboard, I used custom shapes/symbols to represent each hazard and reflected the number of recalls through the size of the symbols. I also used the manufacturing country to create a map of the recalls, were the size of each country bubble is representing the number of recalls (guess which country gets the biggest bubble…). I also added a link to a detail page that has each recall info, and a link to the agency recall web page about the recall. And the sweetest thing, I will not need to touch this dashboard ever again, it refreshes the data from the xml each night automagically.. Be sure to click the image above to visit the live dashboard!
A couple of years ago I published an HTML5 recalls dashboard on this blog (http://bihappyblog.com/2012/12/17/recalls-dashboard/). To create this dashboard, I connected to the Consumer Product Safety Commission web site and converted the xml data it provides into JSON format to be consumed by the HTML5 dashboard. Recently, I ran into the Tableau Extract API and I thought it would probably be interesting to create a Tableau version of this dashboard, in which I could leverage the Extract API to convert the XML feed provided by Consumer Product Safety Commission in Tableau extract format (.tde file). Once that technical hurdle is accomplished, Tableau could be used to create really neat visualizations quickly and easy. What’s more, this illustrates the possibility of connecting Tableau to virtually any data source, currently supported by Tableau or not, since the Extract API can be used to create a .tde file from virtually any data that can be connected to programmatically.
First thing is first, I made sure I followed the Extract API instructions for Eclipse (http://onlinehelp.tableausoftware.com/current/pro/online/windows/en-us/extracting_TDE_API.html). Once my environment was setup, and I was able to run the sample MakeOrder app to produce a .tde file, it did not took much adaptation to write my own class to connect to the CPSC website to obtain the recalls in their XML format, iterate through the XML document and convert it to the Table format needed to produce a Tableau Extract file. Below is the source code for that..
package com.cleartelligence.tableau.extract.api.sample;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.NodeList;
import com.tableausoftware.TableauException;
import com.tableausoftware.DataExtract.Collation;
import com.tableausoftware.DataExtract.Extract;
import com.tableausoftware.DataExtract.Row;
import com.tableausoftware.DataExtract.Table;
import com.tableausoftware.DataExtract.TableDefinition;
import com.tableausoftware.DataExtract.Type;
public final class MakeRecalls {
private static TableDefinition makeTableDefinition() throws TableauException {
TableDefinition tableDef = new TableDefinition();
tableDef.setDefaultCollation(Collation.EN_US);
//Create a table definition based on the recall data
tableDef.addColumn("UPC", Type.UNICODE_STRING);
tableDef.addColumn("country_mfg", Type.UNICODE_STRING);
tableDef.addColumn("hazard", Type.UNICODE_STRING);
tableDef.addColumn("manufacturer", Type.UNICODE_STRING);
tableDef.addColumn("prname", Type.UNICODE_STRING);
tableDef.addColumn("recDate", Type.UNICODE_STRING);
tableDef.addColumn("recallNo", Type.UNICODE_STRING);
tableDef.addColumn("recallURL", Type.UNICODE_STRING);
tableDef.addColumn("type", Type.UNICODE_STRING);
tableDef.addColumn("y2k", Type.UNICODE_STRING);
return tableDef; }
private static void parseRecalls(Table table, String startDate, String endDate) throws Exception {
String insertItem = " ";
TableDefinition tableDef = table.getTableDefinition();
//URL to obtain recalls XML data - added params for the start and end date so they can be passed in from the main method
URL url = new URL("http://www.cpsc.gov/cgibin/CPSCUpcWS/CPSCUpcSvc.asmx/getRecallByDate?startDate="+startDate+"&endDate="+endDate+"&userId=test&password=test");
URLConnection connection = url.openConnection();
//After examining the xml structure, determined the level needed, iterate to the XML node level needed
Document doc = parseXML(connection.getInputStream());
NodeList first = doc.getChildNodes();
NodeList second = first.item(0).getChildNodes();
NodeList third = second.item(1).getChildNodes();
for(int i=0; i<third.getLength();i++)
{
//result rows have recalls data in the xml, parse them into the table
if (third.item(i).getNodeName()=="result") {
NamedNodeMap attr = third.item(i).getAttributes();
System.out.println("Wrote line "+i +" into .tde file");
Row row = new Row(tableDef);
for (int x=0; x < attr.getLength(); x++) {
if (attr.item(x).getNodeValue().length()<1)
insertItem = "NULL";
else
insertItem = attr.item(x).getNodeValue();
row.setString(x, insertItem);
}
table.insert(row);
}
}
tableDef.close();
}
private static Document parseXML(InputStream stream)
throws Exception
{
DocumentBuilderFactory objDocumentBuilderFacto
y = null;
DocumentBuilder objDocumentBuilder = null;
Document doc = null;
try
{
objDocumentBuilderFactory = DocumentBuilderFactory.newInstance();
objDocumentBuilder = objDocumentBuilderFactory.newDocumentBuilder();
doc = objDocumentBuilder.parse(stream); } catch(Exception ex) { throw ex; } return doc;
}
public static void main(String[] args)
{ //start and end date args for the recalls data as yyyy-mm-dd, for example, 2014-12-31
String start = args[0];
String end = args[1];
//path to .tde
Path path = Paths.get("C:\\recallsTDE\\recalls-java.tde");
try {
//remove any prior version of the .tde
Files.deleteIfExists(path);
} catch (IOException e) {
e.printStackTrace();
}
try (Extract extract = new Extract("C:\\recallsTDE\\recalls-java.tde")) {
Table table;
TableDefinition tableDef = makeTableDefinition();
table = extract.addTable("Extract", tableDef);
parseRecalls(table,start,end);
} catch (Throwable t) {
t.printStackTrace(System.err);
}
}
}
The next step was a bit more tricky, as it was not documented anywhere I could find. How to actually use the .tde file in a tableau server environment so that dashboards can be created off it and refreshed automatically? After experimenting with multiple methods, I settled on the following approach: run the extract program as a runnable jar on a server and then use the tabcmd API to publish the data source into my tableau server. The .bat file I created to run the runnable jar and export the .tde into the server looks like so..:
cd C:\recallsTDE
java -jar "C:\recallsTDE\recalls-java.jar" 2000-01-01 2020-12-31
tabcmd publish "C:\recallsTDE\recalls-java.tde" -o -s http://[my.tableau.server.ip] -u [myTableAdmin] -p [myTableauAdminPwd] -t [mySite]
My runnable jar, recalls-java.jar, sits on the C drive in a directory called recallsTDE. It takes the argument 2000-01-01 for the first date to look for recalls from the government web site and 2020-12-31 is the end date.
After the java program finishes running and the .tde is created, it is published to the server with the tabcmd command, which you can lookup as well. Documentation for it is par I guess, but you can kind of make your way through it, it is fairly intuitive.
I put this .bat file into a windows schedule which runs daily and now I have my automatically refreshable tableau server data connection to work with.
The next step was of course to create the dashboard in tableau desktop from the data.
And the final step was to leverage the trusted authentication setup I have with our front facing servers (since tableau server sits behind the firewall) to expose the dashboard via a URL that will bypass the login screen. Here is the code for that step as well:
<%@page session="false"%>
<%@page import="java.net.*,java.io.*" %>
<%
String user = "[TableauUserWithAccessToDashboard]";
String wgserver = "[TableauServerAddress – internal]";
String dst = "views/[workbook]/[view]";
String params = ":embed=yes&:toolbar=no&:tabs=no&:refresh";
String ticket = getTrustedTicket(wgserver, user, request.getRemoteAddr());
if ( !ticket.equals("-1") ) {
response.setStatus(HttpServletResponse.SC_MOVED_TEMPORARILY);
response.setHeader("Location", "http://server/trusted/" + ticket + "/t/site/" + dst + "?" + params);
}
else
// handle error
throw new ServletException("Invalid ticket " + ticket);
%>
<%!private String getTrustedTicket(String wgserver, String user, String remoteAddr)
throws ServletException
{
OutputStreamWriter out = null;
BufferedReader in = null;
try {
// Encode the parameters
StringBuffer data = new StringBuffer();
data.append(URLEncoder.encode("username", "UTF-8")); data.append("=");
data.append(URLEncoder.encode(user, "UTF-8"));
data.append("&");
data.append(URLEncoder.encode("client_ip", "UTF-8"));
data.append("=");
data.append(URLEncoder.encode(remoteAddr, "UTF-8"));
data.append("&");
data.append(URLEncoder.encode("target_site", "UTF-8"));
data.append("=");
data.append(URLEncoder.encode("Site2", "UTF-8"));
// Send the request
URL url = new URL("http://" + wgserver + "/trusted");
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
out = new OutputStreamWriter(conn.getOutputStream());
out.write(data.toString());
out.flush();
// Read the response
StringBuffer rsp = new StringBuffer();
in = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
while ( (line = in.readLine()) != null) {
rsp.append(line);
}
return rsp.toString();
} catch (Exception e) {
throw new ServletException(e);
}
finally {
try {
if (in != null) in.close();
if (out != null) out.close();
}
catch (IOException e) {}
}
}
%>
And there you have it. Enjoy!